 Вход — sdo.rzd.ru/lms
Вход — sdo.rzd.ru/lms Время прочтения: 6 мин.
Анализ данных является довольно сложным, увлекательным и часто требующим креативности от исполнителя процессом. Важным и первостепенным этапом проведение анализа является подготовка данных. Именно этому этапу, от которого зависит скорость, удобство, а также результат, и посвящен мой пост.
Публикация выполнена в виде инструкции с пошаговым прогрессом. Пороговый вход для понимания материала невысокий, но кое-что все же нужно знать:
- типы данных;
- вызов библиотек;
- конструктор для таблиц DataFrame;
- срезы данных.
На входе у нас есть Data Frame с данными о поле (м или ж), возрасте, контактной информацией, а также признаком. Для тех, кто не любит абстрагироваться, признак – это ответ на вопрос «Играете ли вы в компьютерные игры?» и он может принимать одно из двух значений (да или нет).
Шаг 1. Знакомство с данными
На первом этапе важно посмотреть, что за данные у нас на руках: какие столбцы, какие типы данных, какие они принимают значения.
Выведем первые строки методом head():
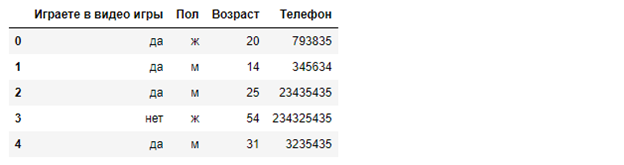
Посмотрим сводную информацию методом info():
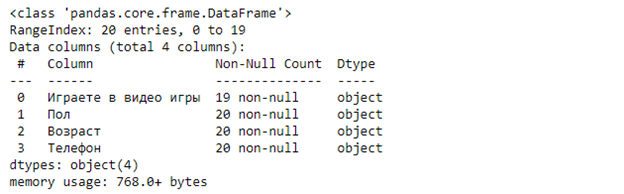
Метод info() дает много информации, из которой мы узнаем, что в таблице 20 строк, 4 столбца, видим типы данных для каждого столбца и количество ненулевых значений.
Шаг 2. Переименование столбцов
Является необязательным шагом, но он делает дальнейшие действия более удобными, а внешний вид приятным. Обычной рекомендацией для названия столбцов является: применение латиницы в названии, нижний регистр, а также отсутствие пропусков в имени столбца (заменяется на символ «_»). Для переименования столбцов применим метод set_axis():

Шаг 3. Пропуски данных
В зависимости от решаемых задач, пропущенные значения могут быть либо удалены методом dropna(). Может быть удален как столбец, в котором есть хоть одно пропущенное значение, так и строка.
- dropna() – удаление строк, где есть пропущенные значения.
- dropna(axis=’col1′, inplace=True) – для удаления столбцов с пропущенными значениями.
В зависимости от данных и решаемой задачи пропущенные значения могут быть заменены на характерные значения: среднее арифметическое или медиана. Также стоит отметить, что пропущенные значения могут «маскироваться» (например под None), для определения этого, можно сначала выполнить поиск уникальных значений методом unique().
Удалим все строки, в которых пропущено значение в столбце ‘tag’ методом dropna():
Заменим пропущенный возраст ‘age’, на средний возраст, характерный для определенного пола с определенным признаком, но перед этим проверим какие уникальные значения принимаются в данном столбце. Затем применим метод replace() к значениям ‘None’ и заменим их на NaN:
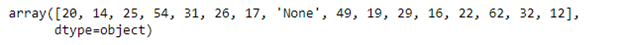
age = df. age. replace(‘None’, np. nan)
Выведем на экран срез данных с пропущенными значениями в столбце ‘age’ применив метод isnull():

Заменим пропущенные значения методом fillna() на средний возраст играющих в компьютерные игры мужчин (пропущенные значения соответствуют этим признакам):

Шаг 4. Дубликаты
Для нахождения дубликатов применяется метод duplicated(), совместно с методом sum() можно определить количество дубликатов.
Для удаления дубликатов используем методом следующую конструкцию:
Метод reset_index() необходим для изменения индексации, так как drop_duplicates() вместе со строками удаляет и их индексы.
Проверим наличие дубликатов:


Удалим дубликаты и проверим результат:
df = df. drop_duplicates(). reset_index(drop=True)
df. duplicated(). sum()

Шаг 5. Изменение типов данных
Проверим как сейчас выглядят наши данные. Для просмотра типа данных воспользуемся атрибутом dtypes:


Для того, чтобы они стали более «нарядными», нужно изменить тип данных в столбцах ‘age’ и ‘phone_num’ на int.
Для перевода значений формата string в числовой формат применяется метод библиотеки Pandas to_numeric(). От значения errors метода to_numeric(), зависят действия при работе с некорректным значением:
- errors=’raise’ — выдается ошибка, операция прерывается;
- errors=’coerce’ — некорректные значения заменяются на NaN;
- errors=’ignore’ — некорректные значения игнорируются, но остаются.
Применим метод to_numeric() к столбцу ‘phone_num’:

Для того, чтобы перевести данные в нужный тип, применяется метод astype():
При вызове метода была получена ошибка:

Она возникает, когда в столбце есть данные, принимающие значения NaN. Решением может быть или замена NaN на 0, или на NA. Заменим на NA и поменяем типы данных в нужных столбцах:
Посмотрим на достигнутый результат:
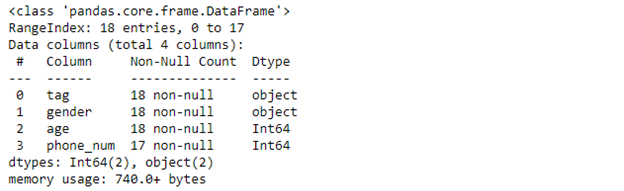

Можно считать задачу решенной, данные подготовлены к дальнейшему анализу.
На этом пост подошел к концу, вспомним чему мы научились:
- Знакомиться с общей информацией, находящейся в таблице.
- Переименовывать столбцы.
- Работать с пропусками.
- Находить и удалять дубликаты.
- Менять тип данных.
Не секрет, что в Excel часто приходится работать с большими таблицами, которые содержат в себе огромное количество информации. При этом подобный объем информации при обработке может стать причиной сбоев или неправильных расчетов при использовании разнообразных формул или фильтрации. Особенно это ощущается, когда приходится работать с финансовой информацией.
Поэтому, чтобы упростить работу с таким массивом информации и исключить вероятность появления ошибок, мы разберем, как именно работать со строками в Excel и использовать их для удаления дубликатов. Возможно, звучит сложно, но разобраться в этом, на самом деле, довольно просто, особенно когда под рукой будет целых пять методов работы с поиском и удалением дубликатов.
- Метод 1: удаление дублирующихся строк вручную
- Метод 2: удаление повторений при помощи «умной таблицы»
- Метод 3: использование фильтра
- Расширенный фильтр для поиска дубликатов в Excel
- Метод 4: условное форматирование
- Метод 5: формула для удаления повторяющихся строк
- Поиск совпадений при помощи команды «Найти»
- Как применить сводную таблицу для поиска дубликатов
- Заключение
Удаление дублирующихся строк вручную
Первым делом следует рассмотреть возможность применения самого простого способа работы с дубликатами. Таковым является ручной метод, подразумевающий использование вкладки «Данные»:
- Для начала необходимо выделить все ячейки таблицы: зажимаем ЛКМ и выделяем всю область ячеек.
- Сверху в панели инструментов нужно выбрать раздел «Данные», чтобы получить доступ ко всем необходимым инструментам.
- Внимательно рассматриваем доступные значки и выбираем тот, который имеет два столбца ячеек, раскрашенных в разные цвета. Если навести на этот значок курсор, то высветится наименование «Удалить дубликаты».
- Чтобы эффективно использовать все параметры этого раздела, достаточно быть внимательным и не торопиться с установками. К примеру, если таблица имеет «Шапку», то обязательно обратите внимание на пункт «Мои данные содержат заголовки», в нем обязательно должна стоять галочка.
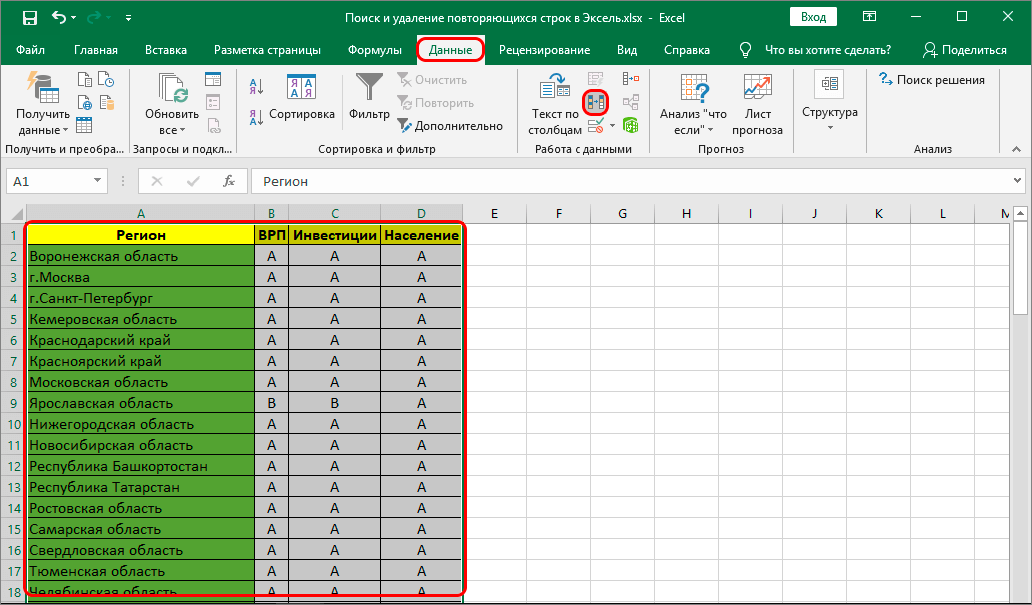
Выделяем таблицу и переходим в раздел инструментария
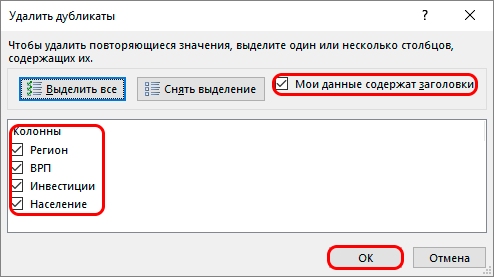
Указываем нужную информацию в окне работы
- Как только все будет готово, еще раз проверьте отмеченную информацию и нажимайте «ОК».
- Программа Excel начнет автоматически анализировать выбранные ячейки и удалит все совпадающие варианты.
- После полной проверки и удаления дубликатов из таблицы в программе появится окно, в котором будет сообщение о том, что процесс окончен и будет указана информация о том, сколько совпадающих строк было удалено.
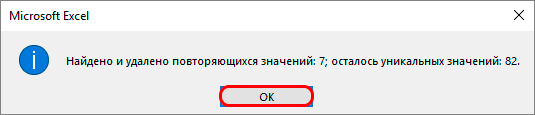
Подтверждаем полученную информацию
Вам остается только нажать на «ОК» и можно считать, что все готово. Внимательно выполняйте каждое действие, и результат вас наверняка не разочарует.
Удаление повторений при помощи «умной таблицы»
Теперь внимательно разберем еще один полезный метод удаления дубликатов, который основывается на использовании «умной таблицы». Достаточно следовать указанным рекомендациям:
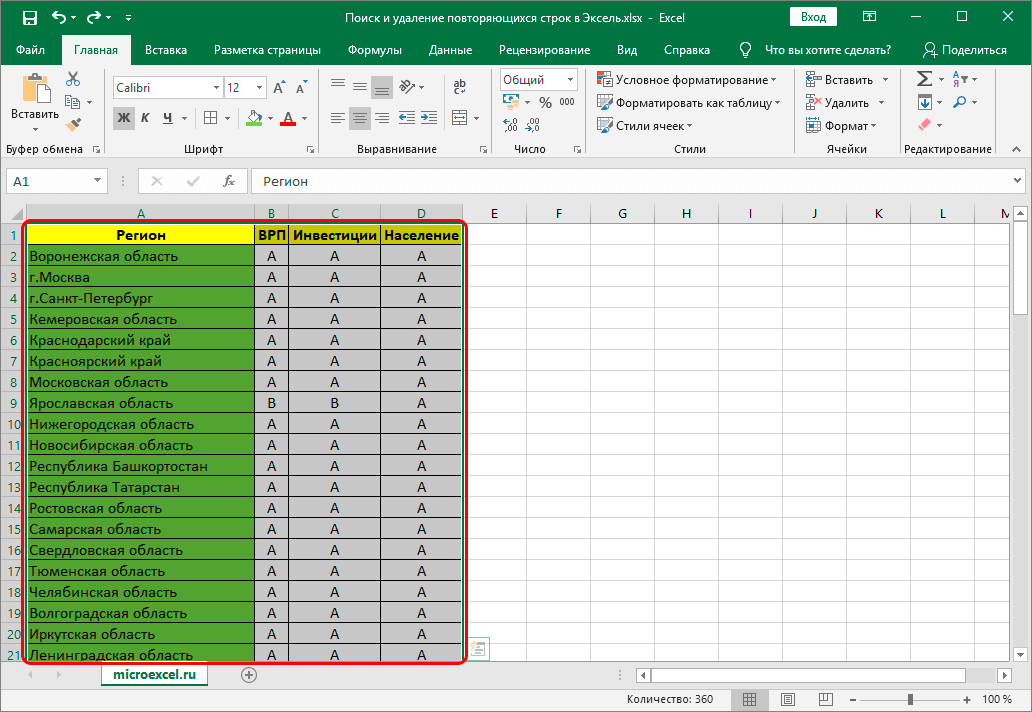
Выделяем нужный диапазон таблицы
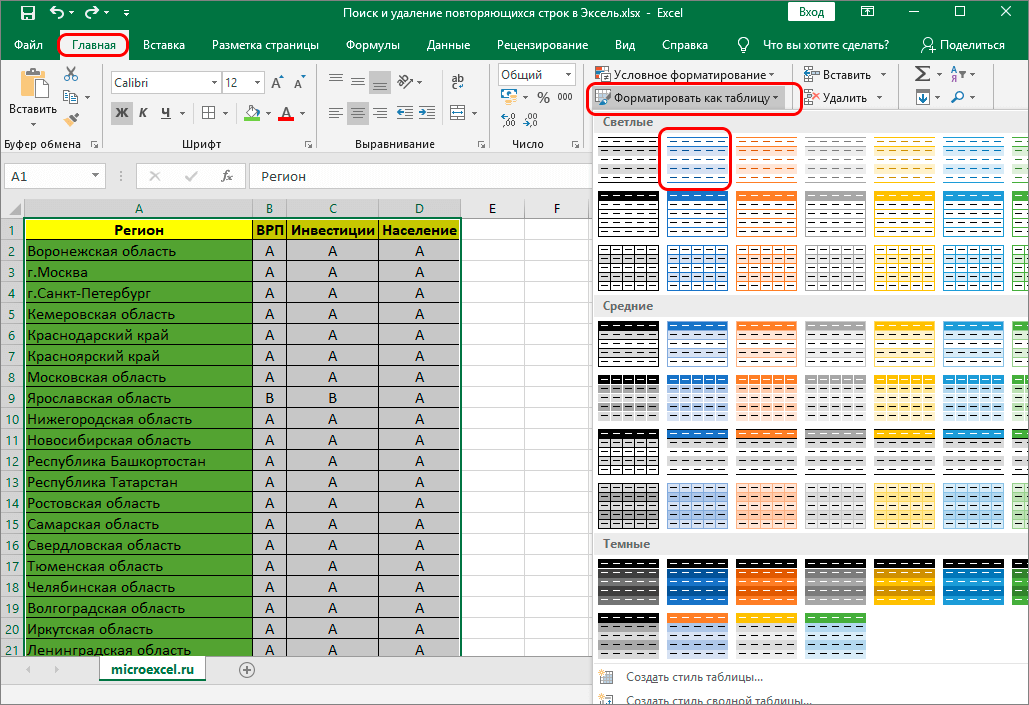
Переходим в панель инструментов для работы со стилем таблицы
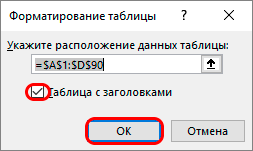
Проверяем и подтверждаем информацию по диапазону таблицы
- Осталось только приступить к поиску и дальнейшему удалению дублированных строк. Чтобы сделать это, необходимо выполнить дополнительные действия:
поставьте курсор на произвольную ячейку таблицы;в верхней панели инструментов нужно выбрать раздел «Конструктор таблиц»;ищем значок в виде двух столбцов ячеек с разным цветом, при наведении на которые будет высвечиваться надпись «Удалить дубликаты»;выполните действия, которые мы указали в первом методе после использования данного значка. - поставьте курсор на произвольную ячейку таблицы;
- в верхней панели инструментов нужно выбрать раздел «Конструктор таблиц»;
- ищем значок в виде двух столбцов ячеек с разным цветом, при наведении на которые будет высвечиваться надпись «Удалить дубликаты»;
- выполните действия, которые мы указали в первом методе после использования данного значка.
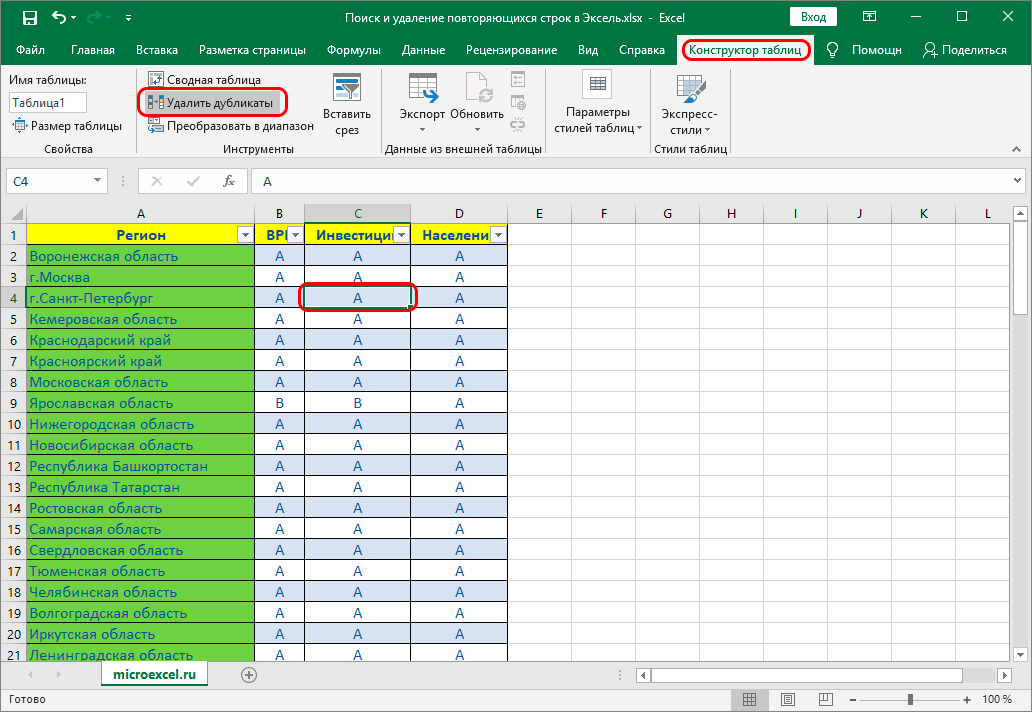
Удаляем найденные дубликаты
Обратите внимание! Данный метод обладает уникальным свойством – благодаря нему можно будет работать с таблицами разного диапазона без каких-либо ограничений. Любая выделенная область во время работы с Excel будет подвергаться тщательному анализу на дубликаты.
Использование фильтра
Теперь обратим внимание на специальный метод, который позволяет не удалить дубликаты из таблицы, а просто скрыть их. По факту этот метод позволяет форматировать таблицу таким образом, чтобы при дальнейшей работе с таблицей вам ничто не мешало и была возможность визуально получить только актуальную и полезную информацию. Чтобы реализовать его, вам достаточно будет выполнить следующие действия:
- Первым делом следует выделить полностью таблицу, в которой вы собираетесь провести манипуляции по удалению дубликатов.
- Теперь перейдите в раздел «Данные» и сразу перейдите в подраздел «Фильтр».
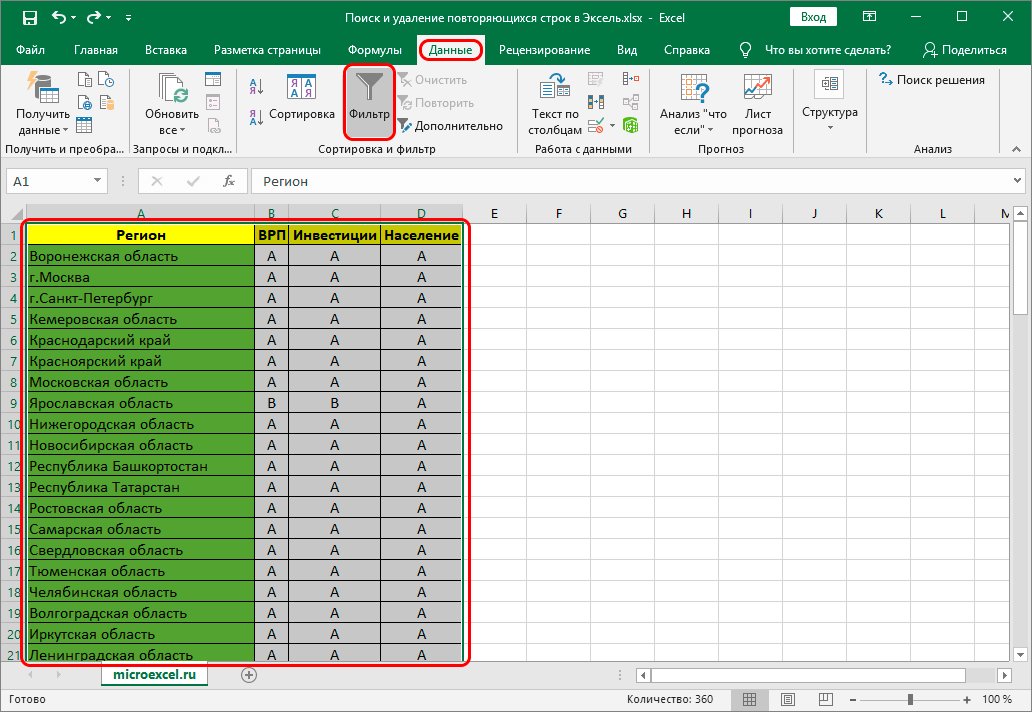
Выделяем диапазон таблицы и используем фильтр
Таким образом можно сразу отфильтровать все дубликаты и произвести дополнительные манипуляции с ними.
Расширенный фильтр для поиска дубликатов в Excel
Имеется еще дополнительный способ использования фильтров в программе Excel, для этого вам понадобится:
- Выполнить все действия прошлого метода.
- В окне инструментария воспользоваться значком «Дополнительно», который находится около того самого фильтра.
Используем расширенный фильтр
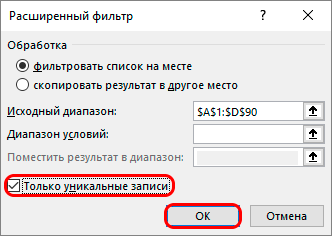
- После использования данного значка вам достаточно будет обратить внимание на окно дополнительных настроек. Этот расширенный инструментарий позволит ознакомиться с первоначальной информацией:
поначалу следует проверить указанный диапазон таблицы, чтобы он совпадал с тем, что вы отмечали;обязательно отметьте пункт «Только уникальные записи»;как только все будет готово, остается лишь нажать на кнопку «ОК». - поначалу следует проверить указанный диапазон таблицы, чтобы он совпадал с тем, что вы отмечали;
- обязательно отметьте пункт «Только уникальные записи»;
- как только все будет готово, остается лишь нажать на кнопку «ОК».
Проверяем и подтверждаем установки фильтра
Проверяем дополнительную информацию после фильтрации
Важно! Если вам необходимо будет вернуть все в изначальный вид, то сделать это максимально просто. Достаточно просто отменить фильтр, выполнив аналогичные действия, которые были указаны в инструкции метода.
Условное форматирование
Условное форматирование – специальный инструментарий, который применяется в решении многих задач. Предусматривается возможность использования этого инструмента для поиска и удаления дубликатов в таблице. Для этого вам понадобится сделать следующее:
Переходим в нужный раздел для форматирования таблицы
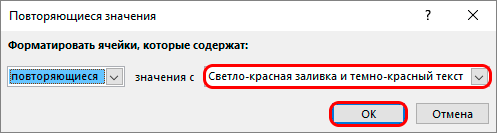
Устанавливаем необходимые значения
Ищем нужную информацию в таблице
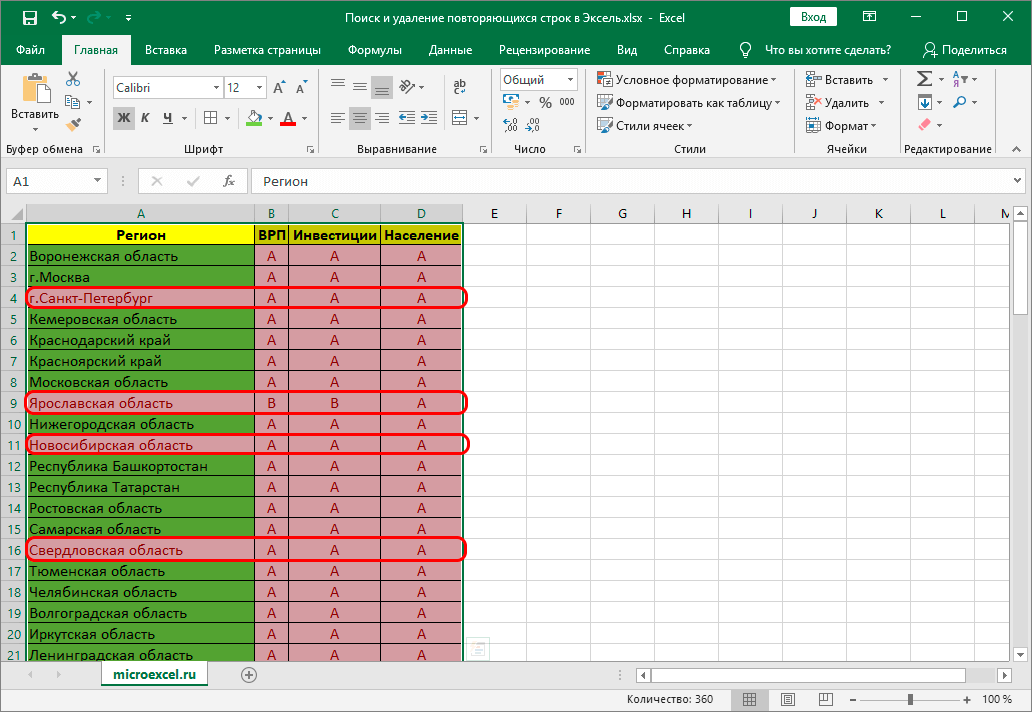
Внимание! Главным недостатком данного метода является то, что при использовании такой функции отмечаются абсолютно все одинаковые значения, а не только те варианты, где совпадает вся строка. Стоит помнить об этом нюансе, чтобы избежать проблем с визуальным восприятием и понять, как именно нужно действовать и на что обращать внимание.
Формула для удаления повторяющихся строк
Данный метод является самым сложным из всех перечисленных, так как предназначается исключительно для тех пользователей, кто разбирается в функциях и особенностях этой программы. Ведь метод предполагает использование сложной формулы. Выглядит она следующим образом: =ЕСЛИОШИБКА(ИНДЕКС(адрес_столбца;ПОИСКПОЗ(0;СЧЁТЕСЛИ(адрес_шапки_столбца_дубликатов:адрес_шапки_столбца_дубликатов(абсолютный);адрес_столбца;)+ЕСЛИ(СЧЁТЕСЛИ(адрес_столбца;адрес_столбца;)>1;0;1);0));»»). Теперь необходимо определиться, как именно ей пользоваться и где применять:
Создаем дополнительный столбец в таблице
- Поставьте курсор в конец формулы, только будьте внимательны с этим пунктом, так как далеко не всегда формулу хорошо видно в ячейке, лучше воспользоваться верхней строкой поиска и внимательно посмотреть правильное расположение курсора.
- После установки курсора необходимо нажать на кнопку F2 на клавиатуре.
- После этого нужно нажать сочетание клавиш «Ctrl+Shift+Enter».
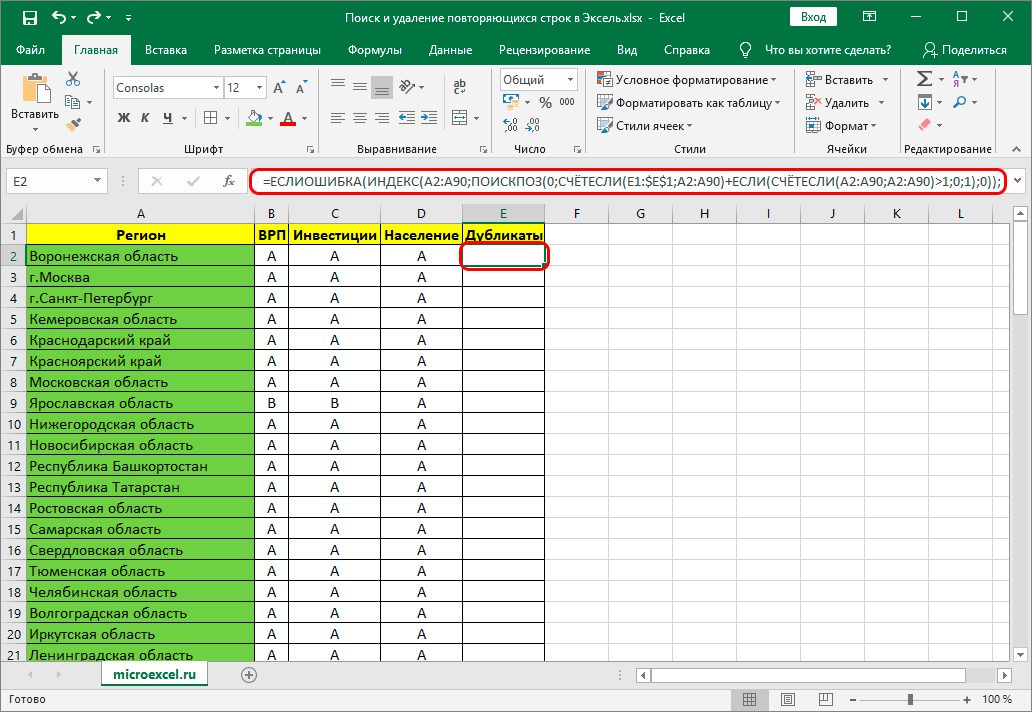
Вставляем и редактируем формулу
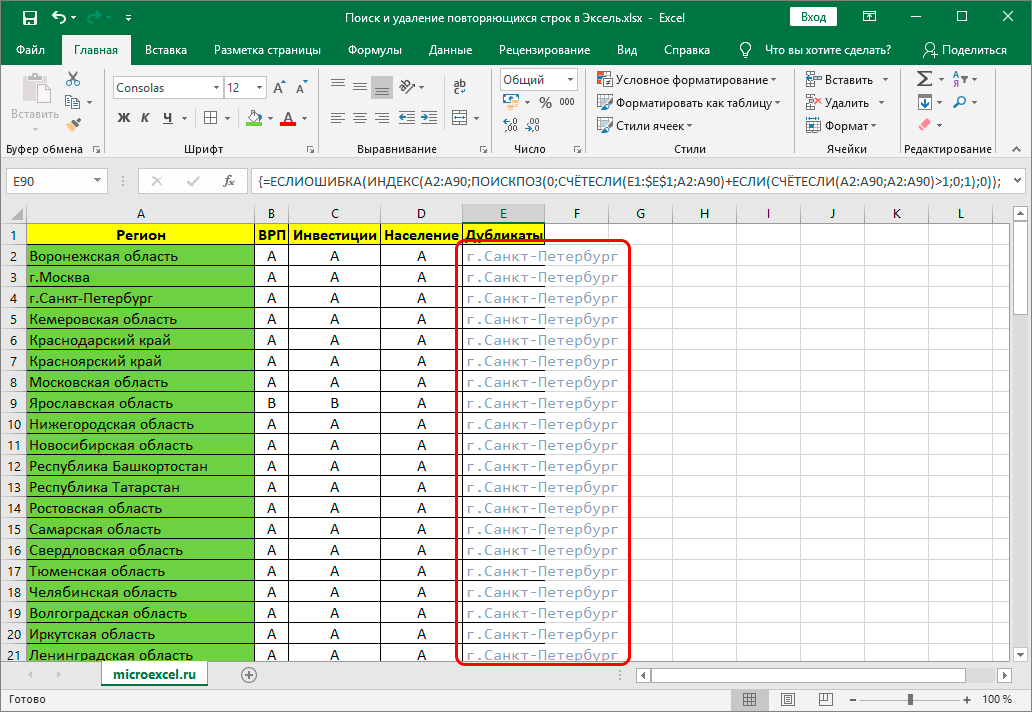
Проверяем полученный результат
Поиск совпадений при помощи команды «Найти»
Дополнительная информация! В данной формуле под А2 подразумеваются отметка первой ячейки из области, в которой вы планируете производить поиск. Как только формула будет введена в первую ячейку, можно протянуть значение и получить нужную информацию. Благодаря таким действиям можно будет распределить информацию на «ИСТИНА» и «ЛОЖЬ». А если вам требуется произвести поиск в ограниченной области, то отметьте диапазон поиска и обязательно закрепите эти обозначения значком $, который подтвердит фиксацию и сделает ее основой.
Если вас не устраивает информация в виде «ИСТИНА» или «ЛОЖЬ», то предлагаем воспользоваться следующей формулой, которая структурирует информацию: =ЕСЛИ(СЧЁТЕСЛИ($A$2:$A$17; A2)>1;»Дубликат»;»Уникальное»). Правильное выполнение всех действий позволит вам получить все необходимые действия и быстро разобраться с имеющимися дубликатами информации.
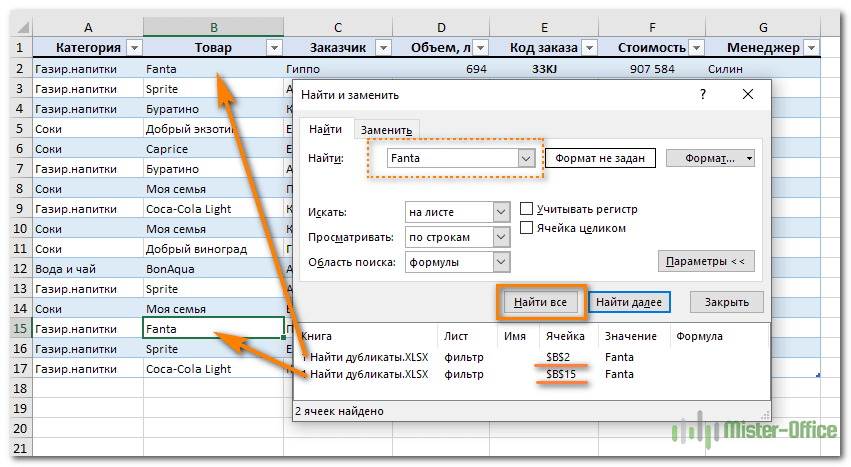
Выполняем действия с командой «Найти»
Как применить сводную таблицу для поиска дубликатов
Дополнительным методом использования функций Excel для поиска дубликатов является сводная таблица. Правда, чтобы ей воспользоваться, все же необходимо базовое понимание всех функций программы. А что касается основных действий, то они выглядят следующим образом:
- Первым делом необходимо создать макет таблицы.
- В качестве информации для строк и значений необходимо использовать одно и тоже поле.
- Выбранные слова совпадения станут основными для автоматического подсчета дубликатов. Только не забывайте, что основой функцией подсчета является команда «СЧЕТ». Для дальнейшего понимания учитывайте, что все значения, которые будут превышать значение в 1, будут являться дубликатами.
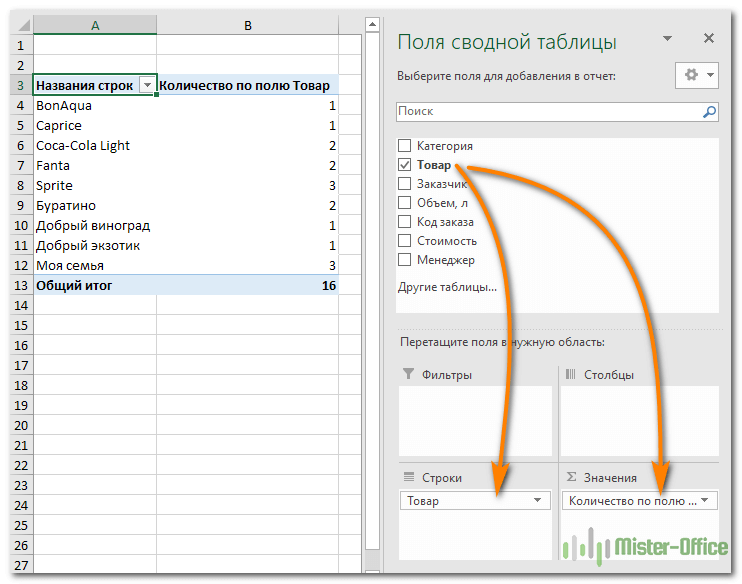
Создаем сводную таблицу
Обратите внимание на скриншот, где показан пример такого метода.
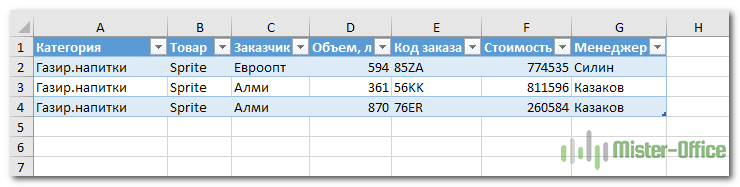
Смотрим результат проверки при помощи сводной таблицы
Главным отличительным пунктом этого способа является отсутствие каких-либо формул. Его смело можно брать на вооружение, но сначала следует изучить особенности и нюансы использования сводной таблицы.
Заключение
Теперь вы владеете всей необходимой информацией касательно методов использования поиска и удаления дубликатов, а также у вас есть рекомендации и подсказки, которые помогут оперативно решить поставленную задачу.
Оцените качество статьи. Нам важно ваше мнение:
Таблицы Excel – это не обычные диапазоны. Ими служит набор данных, с которым можно осуществлять самые разные действия, в том числе, и удаление дубликатов. Важно понимать, что ячейки, которые содержат одинаковые на первый взгляд значения, могут на деле оказаться разных форматов. Очевидно, что Excel может подумать, что они разные, хотя по факту они являются одинаковыми.
Чтобы убрать дубликаты ячеек в таблицах Excel, необходимо знать, как это делается. А проще всего в этом разобраться на конкретных кейсах, что мы сейчас и будем делать.
- Удаление дубликатов с помощью таблиц
- Удаление повторяющихся значений в Excel (версии от 2007 года)
- Расширенный фильтр для удаления дубликатов
- Как выделить дубликаты с помощью условного форматирования (2007+)
- Сводные таблицы для обнаружения повторяющихся значений
- Поиск и выделение дубликатов цветом
- В одном столбце
- В нескольких столбцах
- Дубликаты строк
- Иные способы удаления дубликатов в Excel
- Удаление дубликатов в одном столбце
- Удаление дубликатов в нескольких столбцах
- Удаление дублирующих строк с данными
- Выводы
Удаление дубликатов с помощью таблиц
Для начала надо научиться создавать умные таблицы. Давайте предположим, что мы создали документ, в котором есть диапазон с дублирующимися значениями. Причем форматы этих ячеек отличаются друг от друга количеством знаков после запятой.
Устранять дубликаты можно несколькими способами.
Чтобы сделать это, базируясь на содержимом колонки с текстом, необходимо выполнить следующие действия:
Проверку по столбцу очень важно не забыть выключить, поскольку в ином случае данные не будут удалены.
Удаление повторяющихся значений в Excel (версии от 2007 года)
Допустим, нами была создана таблица, где имеется три колонки. Они содержат ячейки с одинаковыми показаниями, которые нужно убрать. Первый шаг – выделение той области, где есть повторяющиеся ячейки. Есть возможность удалить выделить самые разные диапазоны, включая отдельные столбцы или целую таблицу.
Затем делаем левый клик мышью по вкладке «Данные», и на ней находится кнопка «Удалить дубликаты».
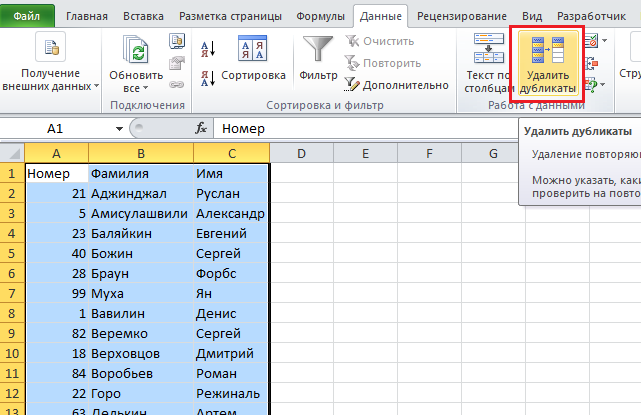
Может быть так, что в таблице есть строка с заголовками. В этом случае нужно поставить соответствующий флажок в открывшемся окне. В нем также нужно выбрать те столбцы, в которых надо искать повторяющиеся значения.
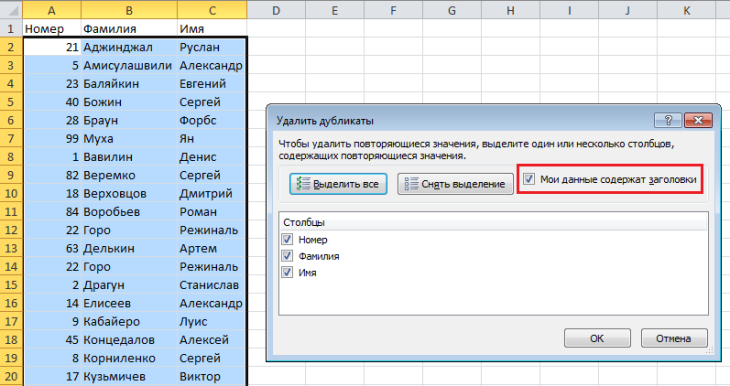
После того, как клавиша ОК будет нажата, все строчки, содержащие дубликаты, убираются.
С помощью этой функции можно удалять ячейки, дублирующие ряды, в полной мере. Впрочем, если была выделена только часть колонок, то все равно уберутся строки, в которых записаны повторяющиеся значения.
Расширенный фильтр для удаления дубликатов
Есть еще один метод удаления ячеек, содержащих одинаковую информацию – расширенный фильтр. Чтобы его применить, нужно выбрать какую-угодно ячейку, находящуюся внутри требуемого диапазона, после чего открыть вкладку «Данные». Нас там интересует кнопка «Дополнительно».
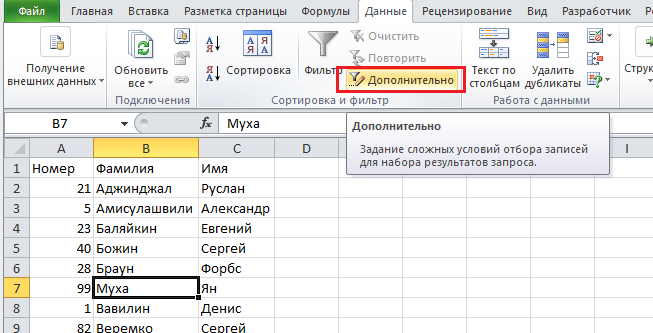
После того, как она будет нажата, откроется окно, где следует выставить опцию «Скопировать результат в другое место», а там, где нужно записать исходный диапазон, надо его указать. Также в этом окошке есть поле «Поместить результат в диапазон», с помощью которого можно задать первую ячейку для будущего диапазона. После этого нужно включить отображение лишь уникальных значений, после чего подтвердить свои действия.
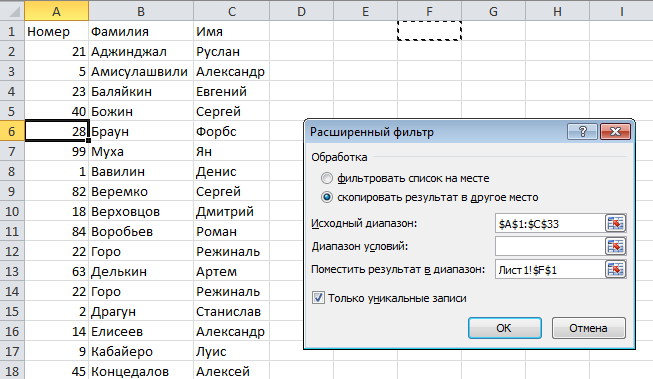
Теперь перед нами появляется таблица с отфильтрованными данными. В ней будут отображаться лишь те значения, которые являются уникальными. Мы так сделали с помощью соответствующей кнопки в предыдущем шаге.
Важно! Этот способ не убирает повторы полностью, а просто их скрывает.
Как выделить дубликаты с помощью условного форматирования (2007+)
Можно также осуществить выделение всех имеющихся дубликатов и убрать их вручную. Для этого можно воспользоваться функцией, которая называется условным форматированием. В качестве первого шага служит выделение таблицы, где нужно осуществить поиск повторяющихся значений. Для этого необходимо найти группу «Стили» на вкладке «Главная», и там найти «Условное форматирование».
Далее следует выбрать непосредственно критерии, по которым будет выделение осуществляться. Нас интересует правило «Повторяющиеся значения».
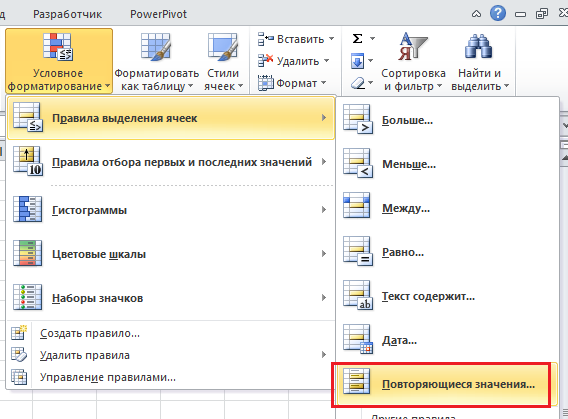
После этого появится окошко, где можно осуществить более гибкую настройку.
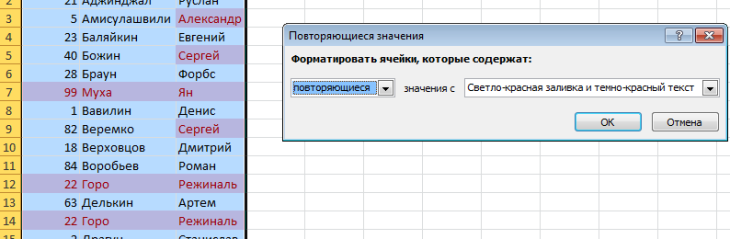
Важно учитывать, что в этом случае форматироваться будет исключительно определенная ячейка колонки, а не строки. Поэтому может быть ситуация, когда повторяющиеся значения одного столбца будут залиты Excel, хотя они не являются уникальными.
Наглядно можно этот эффект увидеть на этом скриншоте.
Сводные таблицы для обнаружения повторяющихся значений
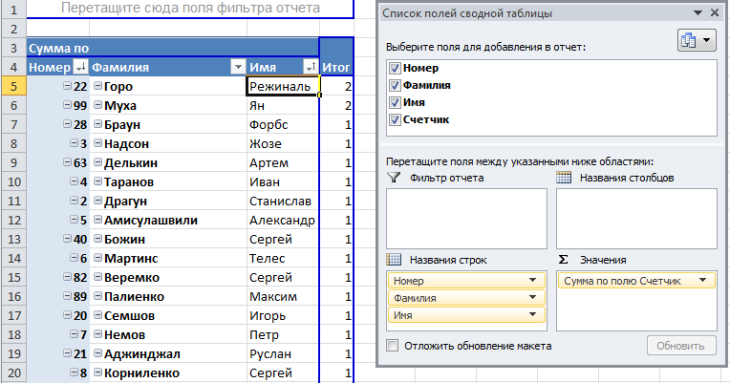
Сводная таблица – это еще один инструмент Excel, использование которого возможно для удаления дублей. Давайте откроем таблицу, которая находится выше (ту, которая с тремя столбцами, и сделаем еще один). Назовем его «Счетчик». В качестве содержимого ячеек будем использовать единицу. После этого вся таблица выделяется. Далее ищем кнопку «Сводная таблица». Найти ее можно на вкладке «Вставка».
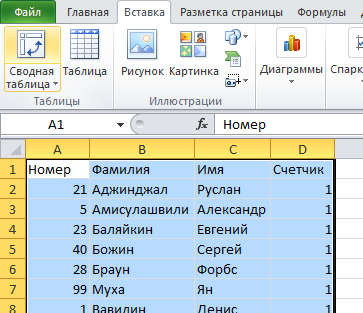
Далее нужно настроить таблицу. Сперва открывается поле «Название строк», где размещается три столбца. Затем в качестве содержимого поля «Значения» выбираем колонку, в которой будет располагаться счетчик.
После этого будет сгенерирована таблица, где те записи, которые содержат число, превышающее единицу, будут обозначать дубликаты. При этом сама цифра будет показывать, сколько значений повторяется. Чтобы было более понятно, давайте сделаем сортировку значений по колонке «Счетчик», чтобы все дубликаты находились вместе.
Поиск и выделение дубликатов цветом
Чтобы выделить дубликаты на фоне других ячеек каким-то цветом, надо использовать условное форматирование. Этот инструмент имеет множество функций, в том числе, и возможность выставлять цвет для обнаруженных дубликатов.
В одном столбце
Условное форматирование – это наиболее простой способ определить, где находятся дубликаты в Excel и выделить их. Что нужно сделать для этого?
- Найти ту область поиска дубликатов и выделить ее.
13 - Далее появляется окно, в котором нужно выбрать пункт «Повторяющиеся» и нажать на клавишу ОК.
15
Теперь дубликаты подсвечены красным цветом. После этого нужно их просто удалить, если в этом есть необходимость.
В нескольких столбцах
Если стоит задача определить дубликаты, расположенные больше, чем в одной колонке, то принципиальных отличий от стандартного использования условного форматирования нет. Единственная разница заключается в том, что необходимо выделить несколько столбцов.
Последовательность действий, в целом, следующая:
- Выделить колонки, в которых будет осуществляться поиск дубликатов.
- Далее снова выбираем пункт «Повторяющиеся» в появившемся окошке, а в списке справа выбираем цвет заливки. После этого кликаем по «ОК» и радуемся жизни.
16
Дубликаты строк
Важно понимать, что между поиском дублей ячеек и строк есть огромная разница. Давайте ее рассмотрим более подробно. Посмотрите на эти две таблицы.
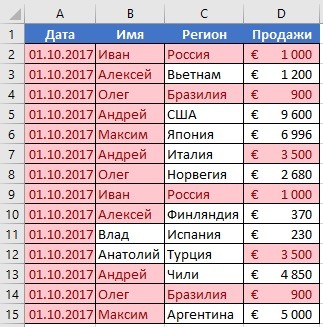
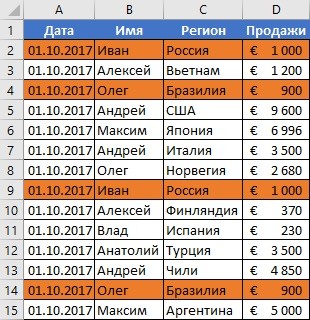
Характерная особенность тех таблиц, которые были приведены выше, заключается в том, что в них приводятся одни и те же значения. Все потому, что в первом примере осуществлялся поиск дубликатов ячеек, а во втором видим уже повторение строк с информацией.
Итак, что нужно сделать для поиска повторяющихся значений в рядах?
- Создаем еще одну колонку в правой части по отношению к таблице с исходной информацией. В нем записывается формула, которая выводит объединенную информацию со всех ячеек, входящих в состав строки. =A2&B2&C2&D2
- После этого мы увидим информацию, которая была объединена.
19 - После этого следует выбрать дополнительную колонку (а именно, те ячейки, которые содержат объединенные данные).
- Далее появится диалоговое окно, где снова выбираем пункт «Повторяющиеся», а в правом перечне находим цвет, с использованием которого будет осуществляться выделение.
После того, как будет нажата кнопка «ОК», повторы будут обозначены тем цветом, который пользователь выбрал на предыдущем этапе.
Хорошо, предположим, перед нами стоит задача выбрать те строки, которые располагаются в исходном диапазоне, а не по вспомогательной колонке? Чтобы это сделать, нужно предпринять следующие действия:
- Аналогично предыдущему примеру, делаем вспомогательную колонну, где записываем формулу объединения предыдущих столбцов.
- Далее мы получаем все содержащиеся в строке значения, указанные в соответствующих ячейках каждой из строк.
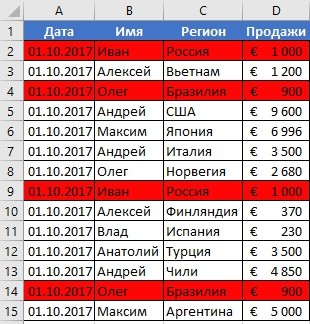
20 - Далее нас интересует пункт «Использовать формулу для определения форматируемых ячеек», после чего вставляем в поле «Форматировать значения, для которых следующая формула является истинной», такую формулу.
22
Для дублированных строк обязательно установить правильный формат. С помощью приведенной выше формулы можно осуществить проверку диапазона на предмет наличия повторов и выделить их определенным пользователем цветом в таблице.
Иные способы удаления дубликатов в Excel
Итак, давайте подведем некоторые итоги касаемо того, как удалять повторы в Excel в разных ситуациях. Начем с повторений в одной колонке.
Удаление дубликатов в одном столбце
Если вся нужная информация находится в одной колонке, а требуется удаление повторяющихся данных, то нужно выполнить такие шаги:
- Выделить нужный диапазон.
- Развернуть вкладку «Данные» на Панели инструментов и найти кнопку «Удалить дубликаты».
24 - После этого появится окно, где возле пункта «Мои данные содержат заголовки» ставится флажок, если в соответствующем диапазоне заголовок имеется. Кроме этого, надо посмотреть на меню «Колонны», чтобы убедиться, что галочка стоит возле нужного столбца.
25
После того, как будет нажата кнопка «Ок», системой будут удалены все копии в столбце.
Удаление дубликатов в нескольких столбцах
Представим, что у нас есть таблица, в которой имена, сумма продаж и регион совпадают, но при этом отличаются даты.
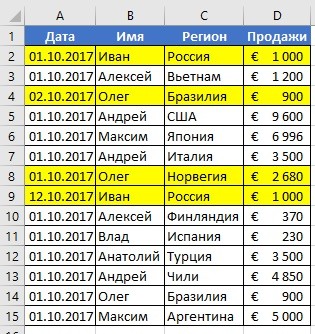
Это может произойти, если при вводе информации в таблицу была допущена ошибка. Если необходимо удалить такие повторения, то нужно осуществить следующие действия:
- Выделить информацию в таблице.
- Развернуть вкладку «Данные», там отыскать часть инструментов, обозначенную заголовком «Работа с данными», после чего кликнуть на знакомую нам кнопку «Удалить дубликаты». Дальше действия осуществляются аналогично, но при нужно не ставить флажок возле столбца с датой.
27
После этого все дубли будут убраны системой.
Удаление дублирующих строк с данными
Чтобы автоматически убрать все повторения строк, нужно выполнить такие действия:
- Выделить часть ячеек, где нужно убрать дубли.
- После этого найти функцию «Удалить дубликаты» и выполнять те же действия, что описаны выше. Но в этом случае надо убедиться в том, что все флажки стоят. Тогда Эксель автоматически проверит всю информацию на предмет наличия в ней повторяющейся.
28
После нажатия ОК мы получаем нужный нам результат.
Выводы
Таким образом, в арсенале Excel есть огромное количество способов, с помощью которых можно скрыть дубли. Не во всех ситуациях нужно удалять их, нередко достаточно просто их спрятать или отметить цветом.
Чтение этой статьи займёт у Вас около 10 минут. В следующие 5 минут Вы сможете легко сравнить два столбца в Excel и узнать о наличии в них дубликатов, удалить их или выделить цветом. Итак, время пошло!
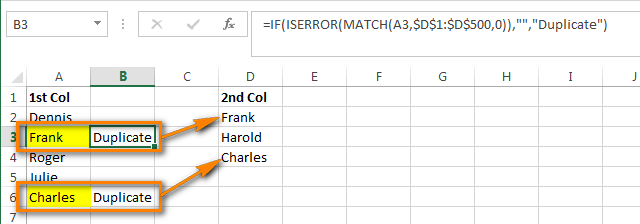
Excel – это очень мощное и действительно крутое приложение для создания и обработки больших массивов данных. Если у Вас есть несколько рабочих книг с данными (или только одна огромная таблица), то, вероятно, Вы захотите сравнить 2 столбца, найти повторяющиеся значения, а затем совершить с ними какие-либо действия, например, удалить, выделить цветом или очистить содержимое. Столбцы могут находиться в одной таблице, быть смежными или не смежными, могут быть расположены на 2-х разных листах или даже в разных книгах.
Представьте, что у нас есть 2 столбца с именами людей – 5 имён в столбце A и 3 имени в столбце B. Необходимо сравнить имена в этих двух столбцах и найти повторяющиеся. Как Вы понимаете, это вымышленные данные, взятые исключительно для примера. В реальных таблицах мы имеем дело с тысячами, а то и с десятками тысяч записей.
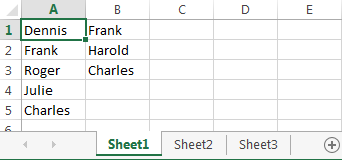
Вариант А: оба столбца находятся на одном листе. Например, столбец A и столбец B.
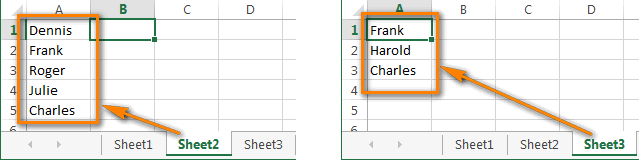
Вариант В: Столбцы расположены на разных листах. Например, столбец A на листе Sheet2 и столбец A на листе Sheet3.
В Excel 2013, 2010 и 2007 есть встроенный инструмент Remove Duplicate (Удалить дубликаты), но он бессилен в такой ситуации, поскольку не может сравнивать данные в 2 столбцах. Более того, он может только удалить дубликаты. Других вариантов, таких как выделение или изменение цвета, не предусмотрено. И точка!
Далее я покажу Вам возможные пути сравнения двух столбцов в Excel, которые позволят найти и удалить повторяющиеся записи.
- Сравниваем 2 столбца и ищем дубликаты при помощи формул
Вариант А: оба столбца находятся на одном листеВариант В: столбцы находятся на разных листах или в разных книгах
- Вариант А: оба столбца находятся на одном листе
- Вариант В: столбцы находятся на разных листах или в разных книгах
- Обработка найденных дубликатов
Показать только повторяющиеся строки в столбце АИзменить цвет или выделить найденные дубликатыУдалить дубликаты из первого столбца
- Показать только повторяющиеся строки в столбце А
- Изменить цвет или выделить найденные дубликаты
- Удалить дубликаты из первого столбца
- Сравниваем 2 столбца в Excel и находим повторяющиеся записи при помощи формул
- Вариант А: оба столбца находятся на одном листе
- Вариант В: два столбца находятся на разных листах (в разных книгах)
- Обработка найденных дубликатов
- Показать только повторяющиеся строки в столбце А
- Изменение цвета или выделение найденных дубликатов
- Удаление повторяющихся значений из первого столбца